Ever wondered how Netflix always seems to know exactly what you want to watch next? The secret behind those eerily accurate suggestions is a movie recommendation system in Python – powered by machine learning algorithms that analyze your viewing behavior and serve up content tailored just for you.
In this guide, you’ll learn how to build your own movie recommendation system in Python from scratch, understand the algorithms behind it, and see how AI tools can supercharge your development process.
What Is a Movie Recommendation System?
A movie recommendation system is a type of information filtering system that predicts a user’s preference for a movie they haven’t seen yet. These systems are widely used in streaming platforms, e-commerce, and social media to personalize user experience.
There are three main types of recommendation approaches:
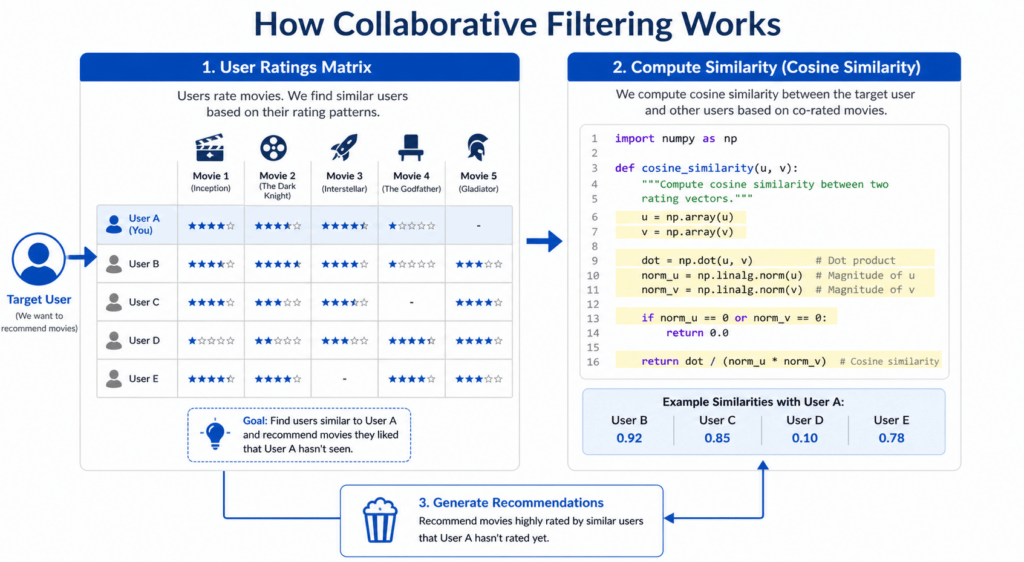
- Collaborative Filtering – recommends movies based on the preferences of similar users
- Content-Based Filtering -suggests movies similar to what a user has already watched
- Hybrid Systems – combines both methods for more accurate results
Building a movie recommendation system in Python allows developers to experiment with all three approaches using powerful libraries like Pandas, Scikit-learn, and Surprise.
Why Python for Building Recommendation Systems?
Python is the go-to language for machine learning and data science projects, and for good reason. It offers a vast ecosystem of libraries, a readable syntax, and strong community support.
Key reasons to use Python:
- Libraries like Pandas and NumPy simplify data manipulation
- Scikit-learn provides ready-to-use ML algorithms
- Surprise library is purpose-built for recommendation systems
- Integration with AI assistants like GitHub Copilot or Claude speeds up development considerably
When building a movie recommendation system in Python, AI-assisted coding helps you write cleaner code, debug faster, and understand unfamiliar algorithms without hours of documentation reading.
Setting Up Your Environment
Before diving into code, set up your Python environment with the necessary libraries.
bash
pip install pandas numpy scikit-learn scikit-surprise
You’ll also need a dataset. The MovieLens dataset (available from GroupLens) is perfect for beginners — it contains millions of ratings from real users for thousands of movies.
python
import pandas as pd
# Load the dataset
movies = pd.read_csv('movies.csv')
ratings = pd.read_csv('ratings.csv')
print(movies.head())
print(ratings.head())
This gives you two DataFrames — one with movie titles and genres, and another with user ratings. Your movie recommendation system in Python starts here.
Building a Content-Based Filtering Model
Content-based filtering recommends movies by analyzing features like genre, director, or cast — and matching them to what a user has previously enjoyed.
python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Use movie genres as the feature
tfidf = TfidfVectorizer(stop_words='english')
tfidf_matrix = tfidf.fit_transform(movies['genres'].fillna(''))
# Compute cosine similarity
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
# Function to get recommendations
def get_recommendations(title, cosine_sim=cosine_sim):
idx = movies[movies['title'] == title].index[0]
sim_scores = list(enumerate(cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:11]
movie_indices = [i[0] for i in sim_scores]
return movies['title'].iloc[movie_indices]
print(get_recommendations('Toy Story (1995)'))
This is one of the fastest ways to get your movie recommendation system in Python up and running. The cosine similarity score measures how closely related two movies are based on their genre features.
Building a Collaborative Filtering Model
Collaborative filtering is more powerful because it uses actual user behavior — not just movie metadata — to make predictions.
python
from surprise import SVD, Dataset, Reader from surprise.model_selection import cross_validate reader = Reader(rating_scale=(0.5, 5.0)) data = Dataset.load_from_df(ratings[['userId', 'movieId', 'rating']], reader) # Train the SVD model algo = SVD() cross_validate(algo, data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
SVD (Singular Value Decomposition) is a matrix factorization technique widely used in movie recommendation systems in Python. It decomposes the user-movie interaction matrix to uncover latent patterns, allowing it to predict ratings even for movies a user has never seen.
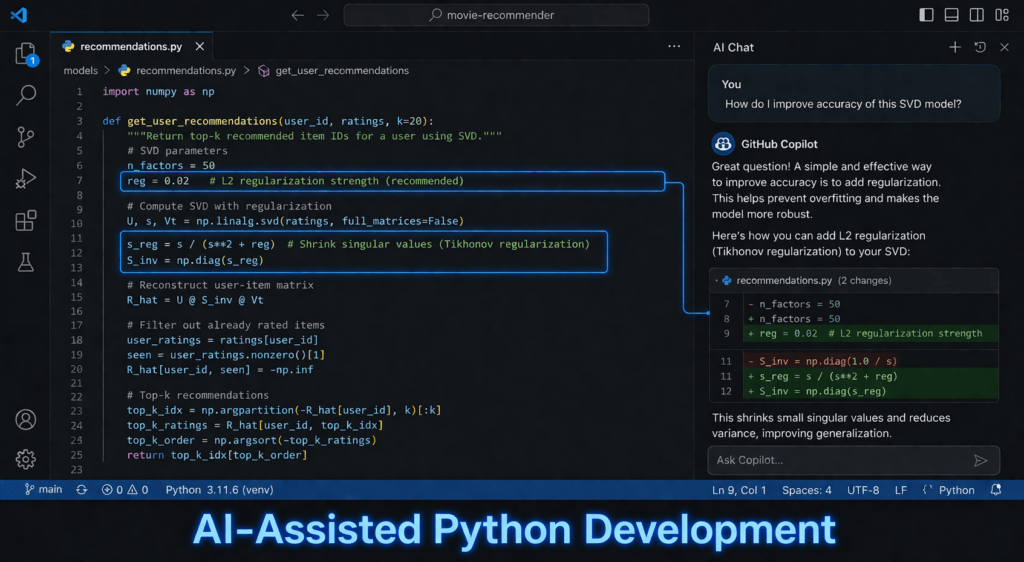
Using AI to Accelerate Development
Here’s where things get exciting. AI coding assistants like Claude or GitHub Copilot can dramatically speed up the development of a movie recommendation system in Python.
Practical ways to use AI assistance:
- Ask the AI to generate boilerplate code for loading and cleaning datasets
- Use AI to explain what matrix factorization does in plain English
- Let AI suggest hyperparameter tuning strategies for your SVD model
- Request AI-written unit tests for your recommendation functions
For example, you can prompt an AI assistant: “Write a Python function that returns the top 10 movie recommendations for a given user ID using collaborative filtering.” The AI will produce a working starting point that you can then modify and test.
This AI-assisted approach to building a movie recommendation system in Python is especially valuable for learners who want to understand the underlying logic without getting stuck on syntax.
Evaluating Your Recommendation System
A movie recommendation system in Python is only as good as its accuracy. Use these standard metrics to evaluate performance:
- RMSE (Root Mean Squared Error) — measures the difference between predicted and actual ratings
- Precision@K — checks if the top K recommended movies are relevant
- Recall@K — measures how many relevant movies appeared in the top K
python
from surprise import accuracy from surprise.model_selection import train_test_split trainset, testset = train_test_split(data, test_size=0.25) algo.fit(trainset) predictions = algo.test(testset) accuracy.rmse(predictions)
Lower RMSE means your movie recommendation system in Python is making more accurate predictions. Aim for an RMSE below 0.90 on the MovieLens dataset as a solid benchmark.
Tips to Improve Your Recommendation System
Once your base model is working, these improvements can take your movie recommendation system in Python to the next level:
- Add demographic data — age, location, or language can refine suggestions
- Incorporate time decay — recent ratings should carry more weight than older ones
- Use a hybrid approach — combine content-based and collaborative filtering outputs
- Deploy with Flask or FastAPI — expose your model as an API so web apps can consume recommendations
- Cache results with Redis — avoid recomputing the same recommendations repeatedly
Final Thoughts
Building a movie recommendation system in Python is one of the most rewarding beginner-to-intermediate machine learning projects you can tackle. It teaches you real-world skills in data wrangling, matrix algebra, model evaluation, and API design — all in a single project.
Whether you’re using the Surprise library for collaborative filtering or Scikit-learn for content-based methods, Python gives you everything you need. And with AI-assisted development tools by your side, you can build, test, and refine your movie recommendation system in Python faster than ever before.
Start with the MovieLens dataset, experiment with both filtering methods, and let AI help you write cleaner, smarter code — one recommendation at a time.
Want to take your Python skills further? Explore more hands-on projects and tutorials at Newtum.Share



