There’s a skill every serious developer is starting to talk about, and it isn’t writing better prompts. It’s knowing what to feed the model before the prompt ever runs.
The industry has quietly crossed a threshold. AI tools are no longer used for isolated, single-shot tasks. They’re being embedded into pipelines, coordinated across multiple agents, and expected to understand entire codebases. In that world, a cleverly worded prompt is the least interesting part of the system. What matters is context engineering for developers, the discipline of architecting the structured information environment that AI models operate in.
This post defines that discipline precisely, introduces the CORE Framework as a practical organizing structure, and gives both junior and senior developers a concrete roadmap to build these skills today.
What Changed: Why Prompts Are No Longer Enough
Prompt engineering made sense when AI was a tool you talked to. You typed a request, got a response, tweaked the phrasing, tried again. The entire skill was about the sentence.
That model breaks down the moment AI becomes infrastructure. When you’re building a multi-step coding agent, an automated review pipeline, or an AI pair programmer with awareness of your full repository, the sentence is not the bottleneck. The bottleneck is context — what the model knows, when it knows it, and in what form.
The shift started with context window expansion. GPT-4 and its contemporaries moved from 4K to 128K tokens. Models can now process entire codebases in a single call. But processing everything is not the same as understanding the right things. What developers discovered is that dumping raw code into the context window produces worse results than deliberately curating what goes in and when.
That curation – structured, systematic, and repeatable is context engineering for developers.
Introducing the CORE Framework for Context Engineering
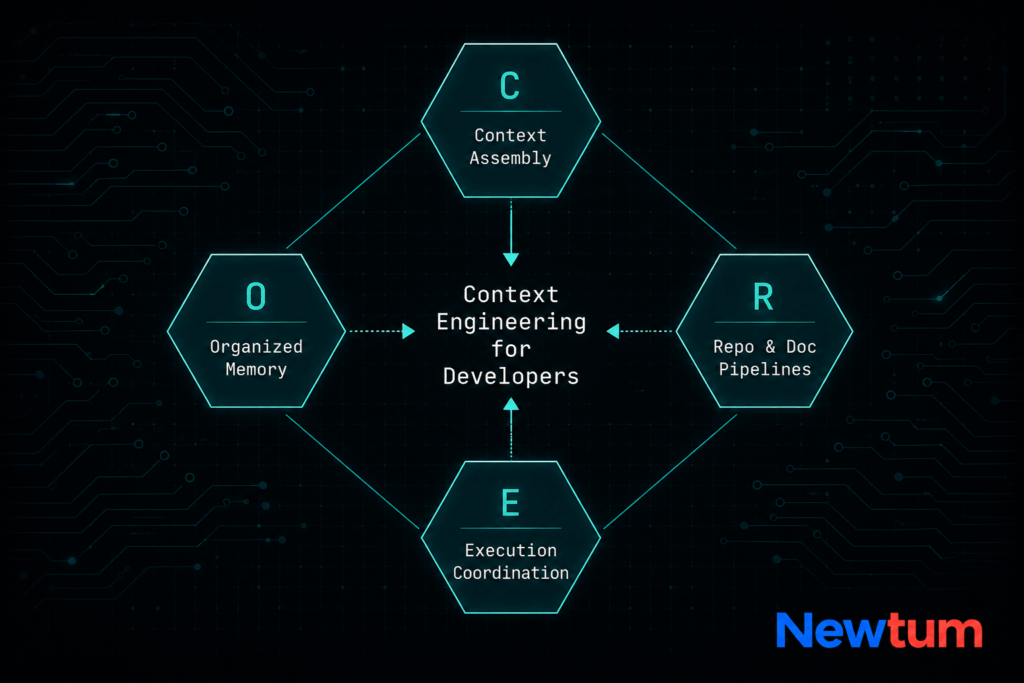
The CORE Framework organizes context engineering for developers into four distinct pillars. Each pillar represents a domain where intentional design produces dramatically better AI outputs than ad hoc prompting alone.
| The CORE Framework C – Context Assembly: What goes into the model’s window and in what structure O – Organized Memory: Persistent state across sessions, tasks, and agents R – Repo and Documentation Pipelines: Automated knowledge feeds from your codebase E – Execution Coordination: Multi-model and multi-agent orchestration logic |
Pillar 1: Memory Systems – Giving AI a Persistent Understanding
Every AI session, by default, forgets everything. Ask an AI coding assistant about your authentication module today, and tomorrow it has no idea it ever helped you. This is the stateless problem, and it’s why developers who rely on naive prompting waste minutes every session re-explaining context that never needed to leave.
Memory systems solve this. In practice, memory operates at three levels:
- In-context memory
Structured data you inject at the start of each session: project name, tech stack, architectural constraints, and naming conventions. This is stored in a file – often called CONTEXT.md or ai-context.yaml — and piped into every prompt automatically. - External memory
A retrieval layer: vector databases, semantic search indices, or document stores. When a query arrives, the system fetches relevant chunks and injects only what’s needed. This is the foundation of RAG (retrieval-augmented generation), and it’s now a production-grade pattern for teams building serious AI tooling. - Episodic memory
Compressed summaries of past sessions. Instead of replaying entire conversation histories, you store structured notes — decisions made, patterns established, errors caught, and inject these as context at the start of new sessions.
Junior developer starting point: Create a CONTEXT.md file in your project root this week. Include: what the project does, the tech stack, key architectural decisions, and anything you’d want a new collaborator to know in the first five minutes. Pipe it into every AI session. The difference in output quality is immediate.
Pillar 2: Repo Context – Making AI Codebase-Aware
Most developers using AI coding tools are giving the model a tiny slice of their codebase and expecting it to make good architectural decisions. That’s like asking an engineer to design a bridge when they’ve only seen one bolt.
Repo context pipelines solve this by systematically feeding relevant parts of your codebase into AI sessions, structured for comprehension rather than just bulk. Core techniques include:
- Selective file injection: automating the selection of files most relevant to the current task based on directory structure, recent git activity, or semantic similarity to the prompt.
- Dependency graphs: generating and injecting a high-level map of module relationships so the model understands how components connect before suggesting changes that affect multiple files.
- Interface and type summaries: stripping out implementation details and injecting only function signatures, type definitions, and interface contracts – the architectural skeleton the model needs to generate compatible code.
- Git diff context: injecting recent commits or PR descriptions alongside the current task to give the model an accurate sense of what’s in motion in the codebase.
| Senior developer note Tools like Cursor, Codeium, and GitHub Copilot do basic repo indexing automatically. Context engineering for developers means going further: building custom context scripts that you control, version, and iterate on — not relying on tool defaults that don’t know your team’s specific architectural priorities. |
Pillar 3: Documentation Pipelines – Automating the Knowledge Feed
Documentation is the most underrated context source in most engineering teams. ADRs (Architecture Decision Records), onboarding guides, API contracts, and post-mortems contain exactly the kind of institutional knowledge that makes AI outputs either genuinely useful or confidently wrong.
The problem is that documentation sits in wikis, scattered Google Docs, or Confluence spaces that no one is systematically piping into their AI tooling. Context engineering for developers treats documentation as a live context feed, not a static archive.
A documentation pipeline at the team level looks like this:
- Trigger-based generation: when a PR is merged, when a sprint closes, or when an architecture discussion ends, a template-driven AI process generates a structured knowledge artifact and commits it to a versioned documentation store.
- Chunked indexing: documentation is broken into semantic chunks, embedded into a vector store, and made retrievable by topic rather than requiring the developer to know which document to search.
- Session injection: at the start of any AI session involving a specific feature area, the relevant documentation chunks are retrieved and injected automatically — no manual copy-paste required.
The payoff is compounding: every decision your team documents becomes immediately retrievable context for every future AI interaction involving that domain.
Pillar 4: AI Coordination – Orchestrating Multi-Agent Systems
The final frontier of context engineering for developers is coordination: designing how multiple AI models or agents pass context to each other, share state, and produce coherent outputs across complex workflows.
This sounds advanced, but the underlying pattern is already common in production engineering. Consider a code review pipeline where:
- Agent 1 reads the PR diff and generates a structured summary: files changed, components affected, potential risks.
- Agent 2 takes that summary and cross-references it against the project’s architecture documentation and past ADRs, flagging conflicts.
- Agent 3 produces the final review comment, informed by both the diff and the architectural context — not just the code surface.
Each agent receives context engineered specifically for its task. The output of Agent 1 is not raw code — it’s a structured context object designed to be consumed by Agent 2. This is the discipline: treating inter-agent outputs as first-class context design problems.
Prompt Engineering vs Context Engineering: What Actually Differs
| Dimension | Prompt Engineering | Context Engineering |
| Unit of work | Single prompt | Context layer / memory system |
| State | Stateless per request | Persistent, structured state |
| Scope | One task at a time | Multi-task, multi-agent flows |
| Memory | None (you re-paste manually) | Embedded: files, summaries, RAG |
| Codebase awareness | What you paste | Repo-wide via context pipeline |
| Documentation | Manual & ad hoc | Automated, trigger-driven |
| AI coordination | Single model | Orchestrated multi-model pipeline |
| Skill ceiling | Craft better sentences | Architect better systems |
Learn Beyond the Prompt Box: How to Build Your Personal AI Engineering Workflow

Junior Developer Playbook: Start Here
If you’re early in your career, you don’t need to build orchestration pipelines in week one. Context engineering has an accessible entry point that immediately improves your output quality.
- Week 1: Create a CONTEXT.md file for every project. Treat it like your AI briefing document. Update it whenever the project changes.
- Week 2–3: Learn what RAG is and why it works. Build a simple example: index 10 documents into a vector store and query them. Tools: LlamaIndex, Chroma, or a managed Pinecone account.
- Month 1–2: Start building context scripts. Write a bash or Python script that compiles relevant file excerpts for a given task and outputs them in a structured format you can paste or pipe into your AI tool.
- Month 3+: Study agent orchestration. Read LangGraph or AutoGen documentation. Build one simple two-agent pipeline: it doesn’t need to be useful, it needs to teach you how inter-agent context handoff works.
The developers who will be genuinely valuable in the next two years of AI tooling aren’t the ones who can write a clever prompt. They’re the ones who can build, maintain, and iterate on context systems.
Senior Developer Playbook: Where to Level Up
If you’ve been in the industry long enough to have built complex data pipelines, distributed systems, or API platforms, you already have the mental models for context engineering. The translation is more literal than you might expect.
- Audit your team’s context debt: How much time do developers spend re-explaining project context to AI tools each day? Measure it informally. That number is your motivation.
- Version-control your context scripts: Treat CONTEXT.md, retrieval scripts, and prompt templates as first-class code artifacts. They belong in your repo with linting and review, not as ad hoc copy-paste habits.
- Build a team context standard: Define what every AI session in your codebase gets by default. This is an architectural decision, and it should be made deliberately, not left to individual developer preference.
- Design for multi-agent context handoff: When evaluating agentic tools or building internal automation, explicitly design the context object each agent receives. Don’t accept tool defaults; specify your schemas.
- Measure context engineering outcomes: Track: time to first usable output per session, PR rejection rates on AI-assisted code, and onboarding time for new engineers using your context system. Context engineering for developers is an engineering discipline — treat it with engineering metrics.
Conclusion: Build the System, Not Just the Sentence
Prompt engineering is not dead in the trivial sense – prompts still exist and still matter. But the discipline of crafting a single better prompt is no longer the skill that separates good AI-assisted developers from great ones.
Context engineering for developers is the emerging discipline that does. It treats the information environment around every AI interaction as an engineering artefact: designed, versioned, tested, and iterated on. Memory systems that persist project understanding across sessions. Repo context pipelines that make codebases legible to models. Documentation feeds that turn institutional knowledge into retrievable context. Multi-agent coordination schemas that make complex workflows coherent. These are the systems skills that AI-era engineering will be built on.
The CORE Framework gives you a map. The playbooks above give you a starting point. What comes next is the work.
| Learn more at Newtum Newtum covers the AI skills, tools, and workflows that matter for developers at every stage. If you’re building your AI-era engineering skillset, explore our courses and blog series on practical AI development — from your first context pipeline to multi-agent orchestration. |
FAQ: Context Engineering for Developers
Q1: Is context engineering for developers actually different from prompt engineering, or just a rebrand?
It’s genuinely different. Prompt engineering is about crafting a single input. Context engineering for developers is about architecting everything that surrounds the model across all requests: memory layers, retrieval pipelines, repo awareness, and multi-agent coordination. The skill set, tooling, and mental model are distinct.
Q2: Do I need to know about context engineering if I’m just using AI for quick tasks?
If you’re running one-off tasks, prompting alone works fine. Context engineering becomes essential the moment you’re building anything multi-step, multi-agent, or production-grade, or any time you want consistent results across long sessions.
Q3: What is the CORE Framework?
CORE is an original framework introduced in this post to organize the four pillars of context engineering: Context Assembly, Organized Memory, Repo and Documentation Pipelines, and Execution Coordination. It’s a practical mental model, not a tool or product.
Q4: How should a junior developer start learning context engineering?
Start with a CONTEXT.md file in your project, then learn the basics of RAG (retrieval-augmented generation). These two habits alone will produce dramatically more consistent AI outputs before you ever touch memory APIs or orchestration layers.
Q5: Does context engineering for developers replace the need for prompt engineering?
No. Prompt engineering is a subset of context engineering. A well-crafted prompt still matters, but it operates within the broader context layer. Think of prompting as one instrument in an orchestra that context engineering conducts.